Are names meaningful? Quantifying social meaning on the web
published at the International Semantic Web Conference 2016 with- Steven de Rooij
- Wouter Beek</li>
- Frank van Harmelen</li>
- Stefan Slobach</li> </ul> </header> According to its model-theoretic semantics, Semantic Web IRIs are individual constants or predicate letters whose names are chosen arbitrarily and carry no formal meaning. At the same time it is a well-known aspect of Semantic Web pragmatics that IRIs are often constructed mnemonically, in order to be meaningful to a human interpreter. The latter has traditionally been termed ‘social meaning’, a concept that has been discussed but not yet quantitatively studied by the Semantic Web community. In this paper we use measures of mutual information content and methods from statistical model learning to quantify the meaning that is (at least) encoded in Semantic Web names. We implement the approach and evaluate it over hundreds of thousands of datasets in order to illustrate its efficacy. Our experiments confirm that many Semantic Web names are indeed meaningful and, more interestingly, we provide a quantitative lower bound on how much meaning is encoded in names on a per-dataset basis. To our knowledge, this is the first paper about the interaction between social and formal meaning, as well as the first paper that uses statistical model learning as a method to quantify meaning in the Semantic Web context. These insights are useful for the design of a new generation of Semantic Web tools that take such social meaning into account.
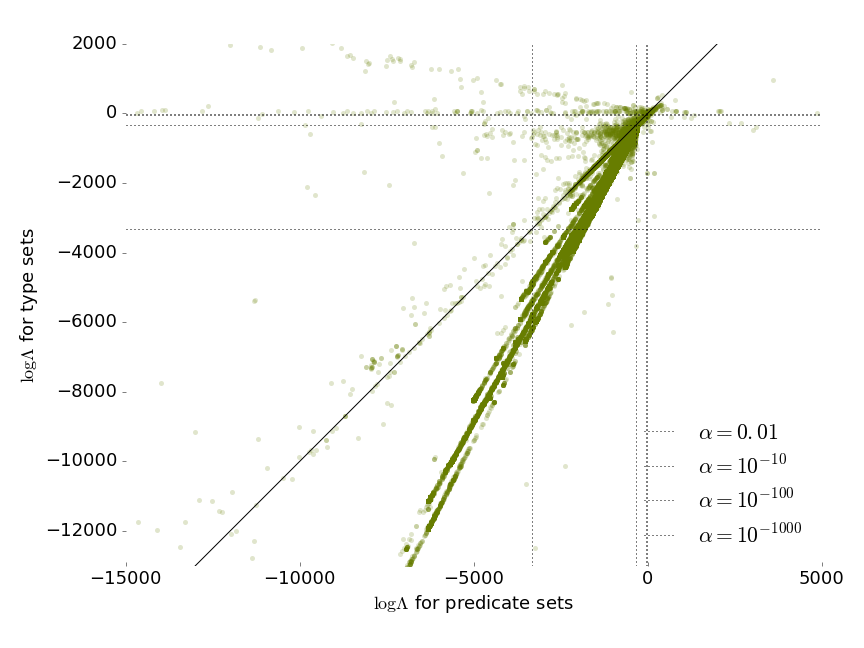
Does an IRI on the Semantic Web allow us to say something about the meaning of the resource it represents? We use type sets and predicate sets as proxies for meaning. We take the null hypothesis that the IRIs contain no meaning, and the type and predicate sets cannot be predicted from the IRI. We then compress the dataset by predicting either the type (vertical axis) or the predicate set (horizontal axis). The more bits we save, the better we predicted the meaning.
The number of bits saved by this compression can be interpreted as a significance values. The dotted lines show the levels of significance at which we can reject the null hypothesis that the IRIs contain no meaning.
- Frank van Harmelen</li>